Tensor Cores, Memory Coalescing, and Constraints
Tensor cores deliver extreme compute density, but their throughput is bounded by scheduling, tiling, and memory movement long before peak FLOPs are reached. This article examines tensor cores as fixed hardware constraints
In the previous article, we establish GPU performance is governed by how well execution aligns with the GPU's memory and scheduling model. Modern GPUs use tensor cores to dramatically increase compute density, making matrix multiplication cheaper by orders of magnitude. Tensor cores assume that the data they need is available, correctly laid out, and reusable. This article examines that assumption directly, focusing on memory coalescing and tensor cores as a single constraint.
Tensor Cores
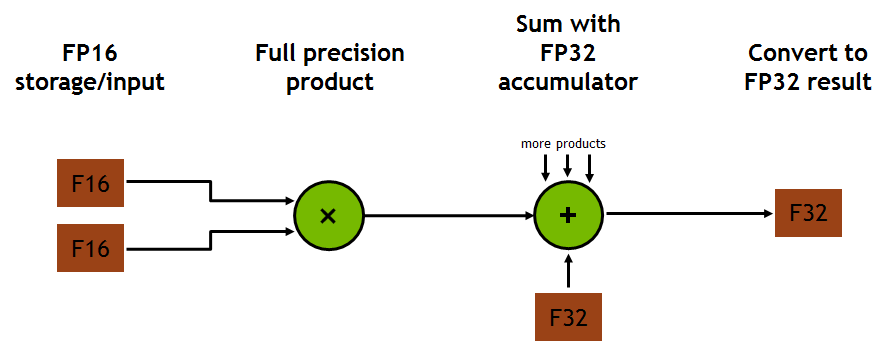
Tensor cores are physical execution units etched onto silicon, meaning their structure, dataflow, and arithmetic are determined at fab and cannot be altered by compilers or frameworks. Tensor Cores implement fixed MMA operation of the form
- D = A x B + C
where A, B, C, and D are small matrices of fixed dimension and types. Dimension and precisions are dictation by microarchitecture. On Volta (V100) a tensor core computes 4x4x4 MMA per cycle using FP16 inputs and FP32 accumulation. This corresponds to 64 multiply adds per cycle per tensor core. On Ampere (A100), tensor cores compute 16x16x16 or 16x8x16 depending on datatype; Hopper adds FP8 and a sparsity-aware variants, but again only at predefined modes.

images from developer.nvidia.com/blog/programming-tensor-cores-cuda-9
Naturally, one wonders why this matters. The point is that Tensor Cores only execute these MMA tiles. Any larger matrix multiplication must be decomposed into these tiles. If the workload cannot be tiled efficiently into the supported MMA shares, Tensor Core utilization falls far short of theoretical FLOPs.
Tensor cores are wired to receive operands from local registers not global memory, meaning the inputs must be resident at issue time. There is no implicit memory access enforcing a strict separation between memory movement and arithmetic.
Tensor Cores are scheduled at the warp level. A warp issues an MMA instruction that maps onto Tensor Cores across the SM. The mapping from warp lanes to matrix fragments is again fixed per architecture. For example on Ampere, one warp issues an mma.sync instruction that engages multiple tensor cores at once. Each thread contributes a fragment of A and B, which is then routed into the Tensor Core array.
Importantly from this section, the Tensor Core pipeline if fixed, but more importantly throughput is capped by issue rate. If your kernel cannot issue MMA instructions every cycle due to memory stalls, register pressure, etc. tensor cores sit idle. Peak theoretical throughput numbers assume perfect tiling, no memory stalls, complete occupancy, and continuous MMA issues, conditions rarely met.
Its important to note that tensor cores and CUDA cores do not replace each other. CUDA handles scalar, vector, address gen, and non MMA math. Tensor cores only accelerate MMA, so operations like softmax and activations run on CUDA cores and can bottleneck the pipeline.
The takeaway is that the model throughput is almost always bound by the slowest non-MMA stage, not by tensor core peak FLOPs. Increasing tensor core performance without changing memory constraints does not linearly improve inference or training speed.
Sparsity support is also rigid. Ampere's 2:4 structured sparsity requires exactly two non zeros per group of four. Any deviation disables sparse tensor core paths; irregular sparsity is ignored and falls back to dense execution.
The implication is tensor cores define what is fast. Models, kernels, and compilers adapt to the frameworks laid out by tensor cores. This explains why some inference workloads scale, why attention shapes matter, or why theoretical FLOPs overestimate real performance.
SM Topology and Warp Scheduling
Tensor cores are embedded inside SMs, and are constrained by SM-level resource caps. Peak throughput is achievable only via continuous MMA instructions made possible by scheduling and data residency optimization.
An SM consists of multiple execution pipelines sharing a finite pool of registers, memory, and warp schedulers. Each warp scheduler can issue at most one instruction per cycle. On modern NVIDIA architectures, an SM contains multiple warp schedulers each responsible for a subset of warps. Instructions issue bandwidth, so if a kernel issues MMA instructions once every N cycles due to instruction mix (loads, stores, arithmetic, control flow), tensor cores are only active 1/Nth of the time.
A second concern is warp residency, determined by shared memory and register usage. An SM can only hold a fixed number of registers. If each thread uses R registers, the maximum number of warps is inversely proportional to R. For example, if a kernel uses 128 registers per thread, and each warp has 32 threads, one warp consumes 4096 registers. With 256k registers (Ampere), the SM can hold at most 64 warps. If the architecture support 64 warps max, occupancy is saturated. But if the kernel uses 102 registers per thread, occupancy drops to ~42 warps. From the previous article we understand more warps means better latency hiding. If there are not enough warps ready to issue, the warp scheduler stalls and tensor cores idle.
A third concern is data movement into registers. Register fragments are loaded from shared memory using load instructions. If shared memory bandwidth is saturated or conflicts occur, another bottleneck forms. For instance, consider a GEMM tile where each warp loads fragments of A and B from shared memory. If each iteration requires 8 shared memory loads and shared memory can sustain only M loads per cycle per SM the max MMA issue rate is bounded by that load throughput, not tensor core throughput. Hence, why shared memory layout matters. Misaligned tiles causes conflicts, increasing effective latency and reducing density of issues.
The fourth bottleneck we'll discuss is dependency chains. MMA instructions produce outputs that may be used by subsequent MMA instructions. If the compiler cannot reorder instructions to break dependencies, the warp is forced to wait for results before issuing the next MMA. This gap typically widens during inference. Training workloads often amortize overhead across large matrices and batches. Inference uses smaller batch sizes producing small GEMMs that udnerfill tiles.
 Roofline model visualization from modal
Roofline model visualization from modal
The key takeaway is tensor cores are downstream of scheduling, occupancy, and memory staging. They are not the dominant factor unless everything upstream is optimal.
Memory Hierarchy Dominates Throughput
A quick recap from last article, GPU memory is structured in a hierarchy: registers -> shared memory -> L1/L2 cache -> HBM. Each level increases latency and bandwidth, where registers are the fastest memory and speed falls off at each subsequent level.
We've mentioned collisions in memory management earlier, but up until now have abstracted away the underlying process. Shared memory is organized into 32 banks. Two or more threads accessing the same bank serialize access. For example, if 32 threads load a fragment and 8 accesses collide, effective latency increases by a factor of 8, stalling tensor cores proportionally. Additionally coalescing remains critical.
If threads access strided elements, global memory transactions multiply. For example a warp of 32 threads accessing FP16 values with stride 64 bytes requires 32 HBM transactions instead of 1-2, increasing latency and starving Tensor Cores.
The intuition behind this is as follows: On NVIDIA GPUs HBM requests fetches one cache line (typically ~128 bytes). In FP16 (2 bytes) if memory is coalesced, next to each other, then 1-2 cache lines span all values. If instead, memory is strided by 64 bytes (meaning there is 64 bytes of space between thread A and thread B and so on) then it follows we need 32 cache lines to span all values
With a recurring theme, the takeaway here is that Tensor Cores accelerate compute only if data can reach them at the required rate. Poor alignment or insufficient tiling caps throughput by creating bottlenecks upstream of the tensor core. In practice, this is exactly the case. Transformer inference is dominated by memory traffic. KV cache grows linearly with context tiles are accessed once per token; batches are small; overall memory stalls dominate.
Tiling and Arithmetic Intensity
Tensor core throughput is determined by arithmetic intensity, FLOPs per byte of memory moved, not raw theoretical FLOPs. Arithmetic intensity is bounded by tile size, mem hierarchy, and reuse. Tile design therefore is a lever for translating tensor core peak into performance.
Consider a GEMM of matrices A and B producing C. Tensor cores operate on fixed size fragments (tiles), typically 16x16 or 16x8 depending on architecture and datatype. A single 16x16 FP16 tile requires 16x16x2 or 512 bytes per input matrix. The total memory staged per GEMM is ~1.5KB. The operation count per MMA is 16x16x16 multiply accumulates = 4096 FMAs = 8192 FLOPS. Arithmetic intensity is calculated as 8192 FLOPS ÷ 1536 bytes ~ 5.3 FLOPs per byte.
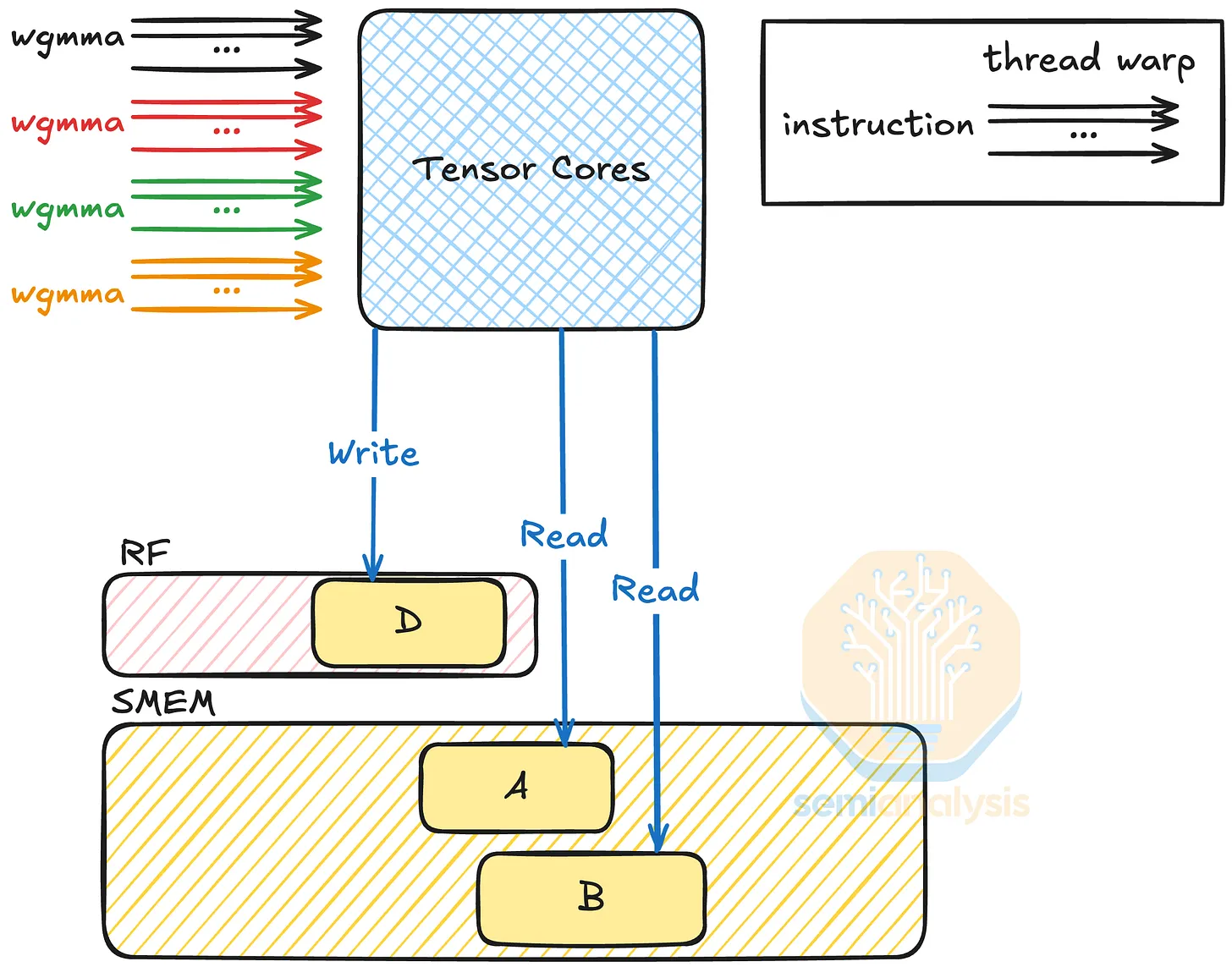 Source - SemiAnalysis
Source - SemiAnalysis
This is notably a lower bound. Increasing tile reuse improves intensity. For instance if the same tiles of A and B are reused four times to compute different tiles of C, memory traffic is reduced by 4x, raising arithmetic intensity to ~21 FLOPs per byte.
This reuse comes from the M and N dimensions where A (MxK) and B (KxN), as well as k blocking from the reduction dimension C (MxN).
Registers constrain tiling. Each thread in a warp stores fragments of A, B, and C. Excessive register usage reduces occupancy, decreasing warps and hindering latency. Shared memory imposes similar limits. There is thus a tradeoff for larger tiles increasing arithmetic intensity, but reducing occupancy. Batch size further constrains effective tiling.
In training large batches produce many tiles enabling continuous feed to tensor cores. For inference, smaller batch size produces scarce tile count, undersaturating warps. Attention layers exacerbate the problem; reuse is limited since each tile participates in only one row column multiplication per token. Each token requires streaming tiles sequentially. Reuse across tokens is minimal. Effective arithmetic intensity collapses unless tokens are batched, which is often infeasible in practice. Attention layers expose the structural limits of tensor cores because they are both arithmetic and memory bound.
Tensor cores are absurdly fast, but in practice they righten memory constraints, scheduling limits, and data movement costs. As compute becomes cheaper per operation any inefficiency upstream dominates. Don't take this as tensor cores are ineffective, but rather they are defined by a narrow region of optimal execution. Models, kernels, and compilers that fall inside that region scale extremely well; those that do not do not. Thus, the importance of understanding broader hardware as a constraint in hardware-software codesign not a separate optimization problem.